This topic describes how you can detect and solve PostgreSQL checkpoints ratio issues
What happened?
To detect checkpoints ratio issues, and have an ability to look in some historical metrics of this – you must have some kind of monitoring solution. Today, there is a rich selection of monitoring solutions – you can use any you already have, or install another one. Here we will discuss samples based on Awide management and monitoring solution.
This alert description includes the following terms: WAL and Checkpoint. You can click on links to see and familiarize with those terms.
Checkpoint operation forces a transaction log checkpoint, flushing all dirty data pages to disk and writing a special checkpoint record to the WAL file. It’s done to minimize the amount of WAL REDO in the process of crash recovery.
There is two checkpoints types:
- Automatic (or scheduled) – It’s a desirable event type
- Required – It’s a problematic event type
Often a checkpoint of required type can cause a significant I/O load, so the system measures the ratio of checkpoints.
If 50% of checkpoints in the measured period were required type – system will raise warning alert. If this value exceeds 75% the system will raise a problem alert.
Why did it happen?
Checkpoint tile located at right side of instance overview.
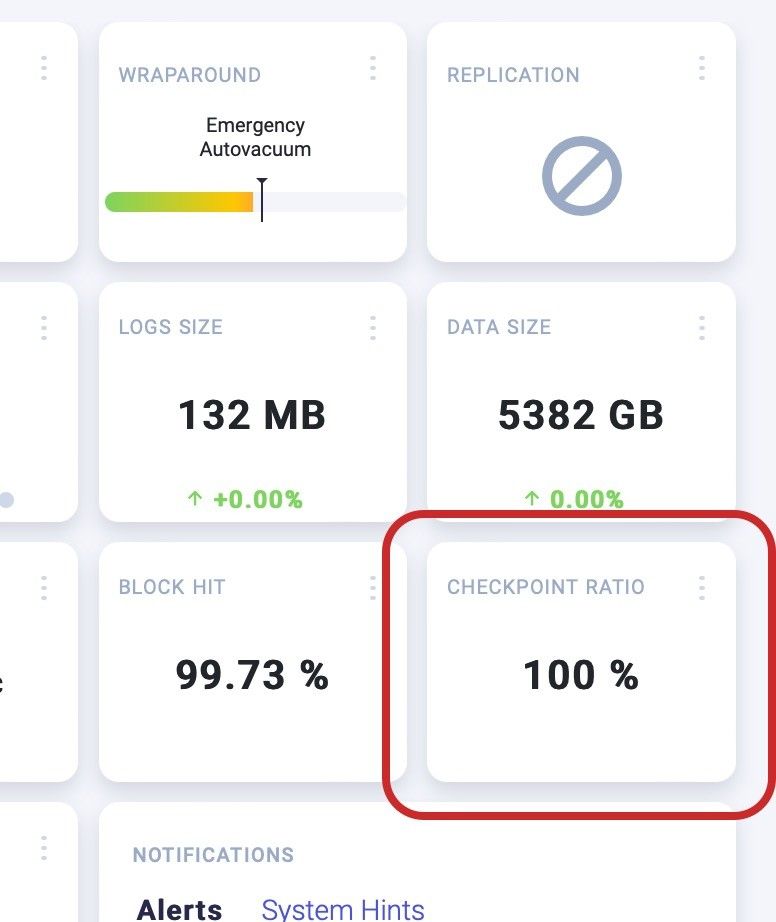
PostgreSQL – Checkpoints Ratio Dashboard
Open the pop out window (click on three dots) and check the chart for the last 3 or 8 hours. Your system raised required checkpoints instead of automatic. So you will see most red line graph, like this:
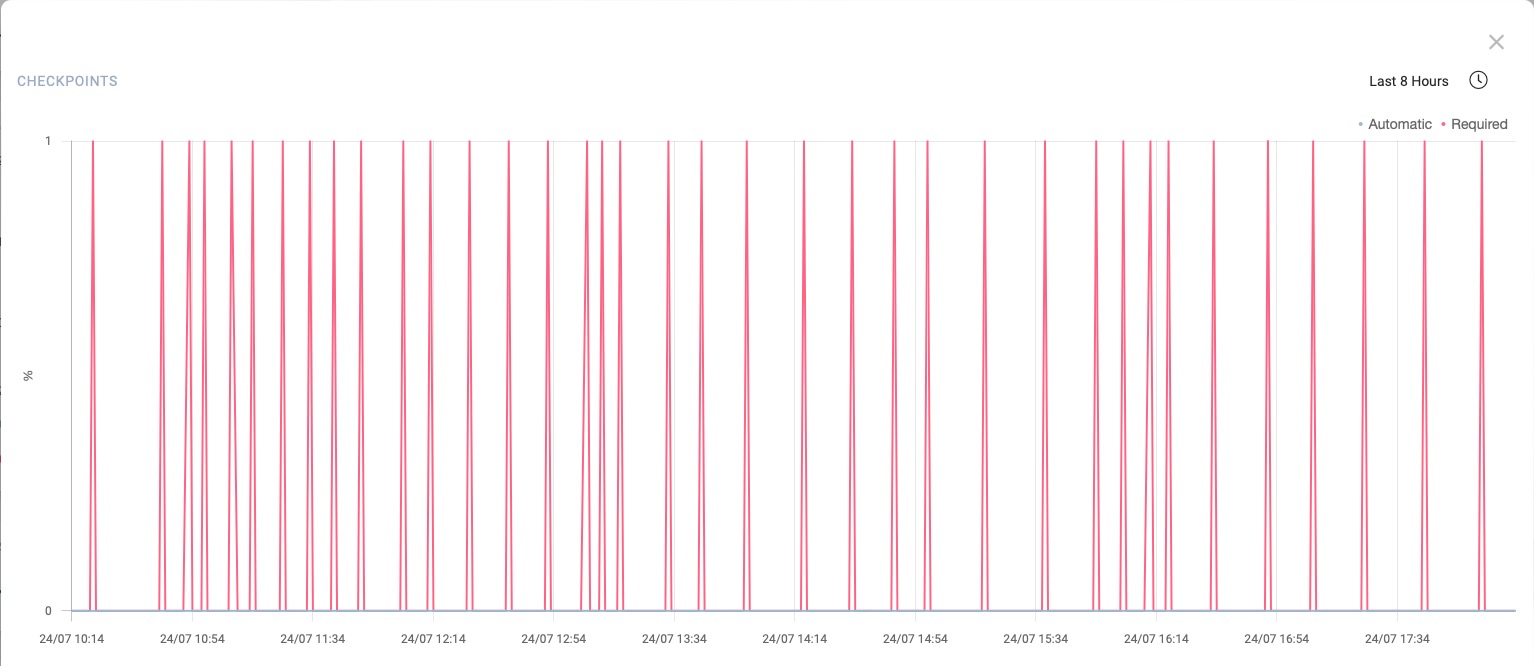
PostgreSQL Checkpoints Ratio – Required Checkpoints
Correct checkpoint work should consist of automatic checkpoints representing with blue graph:
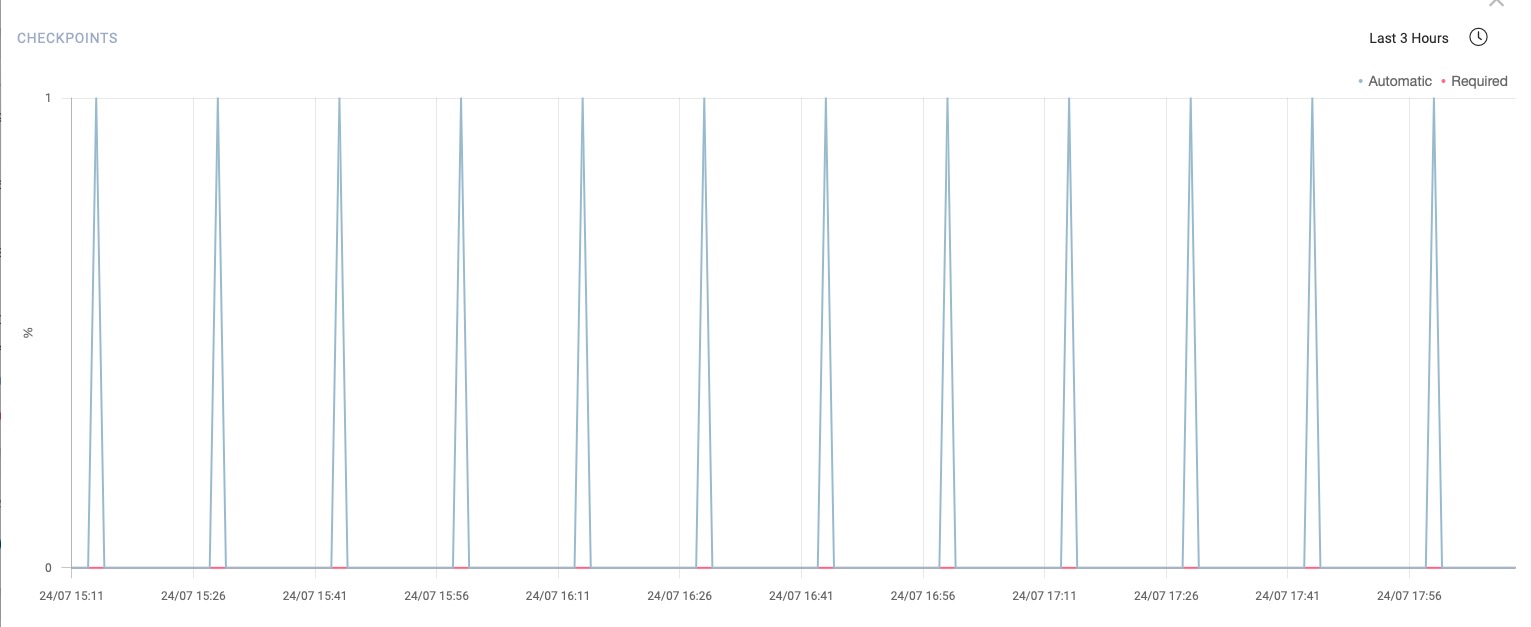
PostgreSQL Checkpoints Ratio – Scheduled Checkpoints
The alert reason is that the checkpoint chart should be like a blue, instead of the red above.
How to solve it?
Two following configuration parameters influence checkpoint behavior: checkpoint_timeout and max_wal_size.
A checkpoint started every checkpoint_timeout seconds, or if max_wal_size is about to be exceeded, whichever comes first.
Open system Configurations screen and find checkpoint_timeout and max_wal_size values. You can use Write-Ahead Log/Checkpoints selection filter:

PostgreSQL Checkpoints Ratio – Configuration
You can use recommended values or calculate them by yourself. Then click on “Apply” to make new values effective. PostgreSQL should improve behavior to perform more scheduled checkpoints. If required checkpoints still often occur, try to increase those values by 2%-5% each time till you will find proper values.