Introduction
Recently we were approached by one of our clients with an interesting task. The fact is that he has a large database, around 1.5 TB. He also has several standbys from this primary server. The main task is to get the opportunity to perform long analytical queries, and also to connect using ETL tools to the replica. But the main problem is that when performing such queries on the replica, the primary server will be affected. There may be replication conflicts and other unpleasant moments. Therefore, the customer asked to reduce the maximum impact on the primary server. In addition, these requests are of a periodic nature and a replica is not always necessary.
Possible solutions
Using Stream Replication
The first thing that comes to mind is to create another PostgreSQL standby server. Streaming replication is the fastest way to deliver changes from one server to other PostgreSQL server. But this can lead to replication conflicts and some other problems. Some words from documentation:
Conflict cases include:
- Access Exclusive locks taken on the primary server, including both explicit
LOCKcommands and various DDL actions, conflict with table accesses in standby queries. - Dropping a tablespace on the primary conflicts with standby queries using that tablespace for temporary work files.
- Dropping a database on the primary conflicts with sessions connected to that database on the standby.
- Application of a vacuum cleanup record from WAL conflicts with standby transactions whose snapshots can still “see” any of the rows to be removed.
- Application of a vacuum cleanup record from WAL conflicts with queries accessing the target page on the standby, whether or not the data to be removed is visible.
Actions from WAL have already occurred on the primary server, so is required to apply them on the standby server. Moreover, allowing a WAL handler to wait indefinitely can be extremely undesirable, since the backlog of the standby server from the primary can increase. Thus, the mechanism provides for forced cancellation of queries on the standby server, which conflicts with the WAL records used. We can use the max_standby_streaming_delay parameter to avoid these problems.
Of course, we can use the max_standby_streaming_delay parameter to avoid these problems. But what about the fact that the replica is needed periodically? If we stop the server, then there will be an accumulation of WAL files on the primary server. Of course they can be archived, but as mentioned above, we want to reduce the impact on the master.
Using Log Shipping with archive command
If we continuously feed the series of WAL files to another machine that has been loaded with the same base backup file, we have a warm standby system.
To enable WAL archiving, set archive_mode to on, and specify the desired shell command in the archive_command parameter. In practice, these parameters are always specified in the postgresql.conf file. In archive_command, the % p characters are replaced by the full path to the file to be archived, and % f is replaced only with the file name. This method requires very careful tuning and the possibility of error is great. For example, it is important that the archive command returns a null exit code, if and only if it completes successfully. Having received a null result, PostgreSQL will assume that the file is successfully archived and will delete it or recycle it.
Using pg_receivexlog (pg_receivewal) and pg_standby
In order to copy WAL-segments there is an alternative method. Use the pg_receivexlog(pg_receivewal) utility. pg_receivexlog is used to stream the transaction log from a running PostgreSQL cluster. The transaction log is streamed using the streaming replication protocol, and is written to a local directory of files. This directory can be used as the archive location for doing a restore. pg_receivexlog can use replication slots that will not allow the un-copied segments to be removed from the master.
For hot standby mode, we will use pg_standby . pg_standby supports creation of a “warm standby” database server. It is designed to be a production-ready program, as well as a customizable template should you require specific modifications.
pg_standby is designed to be a waiting restore_command, which is needed to turn a standard archive recovery into a warm standby operation. Utility is a more convenient tool for organizing a warm standby. It has options that allow you to manage the recovery and size of the archive.
The scheme is as follows:
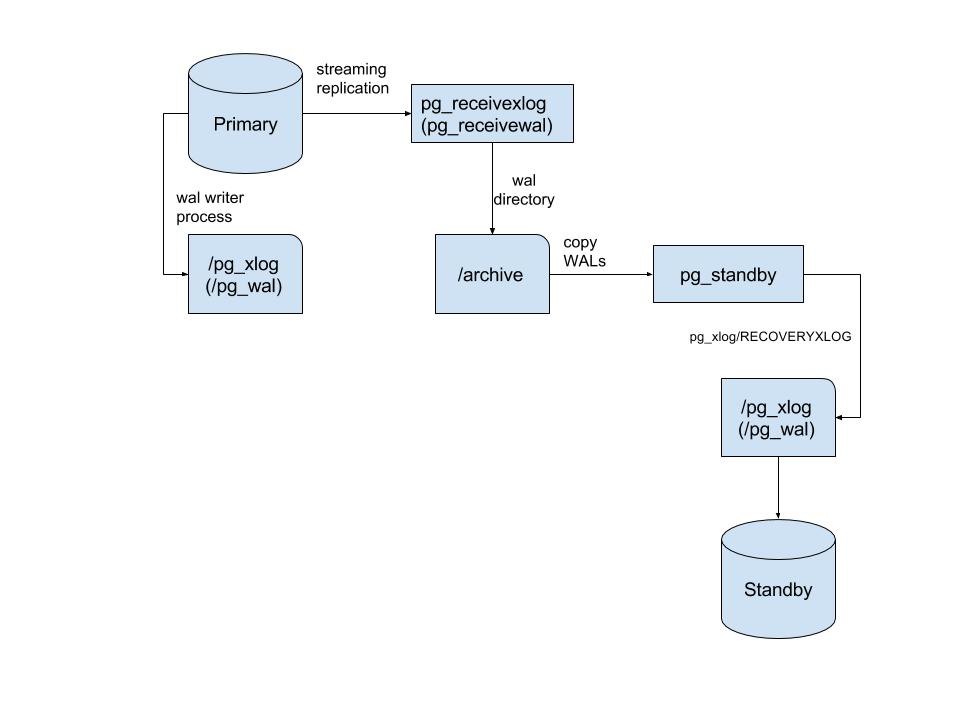
Example of setting
Environment
- Debian GNU/Linux 8.9 (jessie).
- PostgreSQL 9.6.6
- Primary – 10.0.0.180
- Standby – 10.0.0.181
Standby PostgreSQL
Create a directory for WAL files:
mkdir /opt/archive ; chmod -R g-rwx,o-rwx /opt/archive ; chown -R postgres.postgres /opt/archive
Copy the data from the master:
rm -rf /var/lib/postgresql/9.6/main/* pg_basebackup -D /var/lib/postgresql/9.6/main/ -h 10.0.0.180 -p 5432 -U repl -W --xlog-method=stream
Create recovery.cong file:
nano /var/lib/postgresql/9.6/main/recovery.conf restore_command = '/usr/lib/postgresql/9.6/bin/pg_standby -l -d -s 2 -r 10 /opt/archive %f %p %r 2>>/tmp/pg_standby.log'rt=5432'
Change the max_standby_archive_delay parameter to 5 hours:
nano /var/lib/postgresql/9.6/main/postgresql.conf max_standby_archive_delay = 300m
Permissions:
chmod -R g-rwx,o-rwx /var/lib/postgresql/9.6/main/ ; chown -R postgres.postgres /var/lib/postgresql/9.6/main/
service postgresql startroot@srv-test-db2:# ps aux | grep postgres postgres
25286 0.0 0.4 71140 5172 ? S Jan10 0:04 /usr/lib/postgresql/9.6/bin/pg_receivexlog -h 10.0.0.180 -D /opt/archive -S repl_slot -s 5 -U repl --synchronous
postgres 26876 0.0 1.7 236580 18548 ? S 10:43 0:00 /usr/lib/postgresql/9.6/bin/postgres -D /var/lib/postgresql/9.6/main -c config_file=/etc/postgresql/9.6/main/postgresql.conf
postgres 26878 0.0 0.4 236648 4984 ? Ss 10:43 0:00 postgres: 9.6/main: startup process waiting for 00000001000000040000001C
postgres 26884 0.0 0.3 236580 3664 ? Ss 10:43 0:00 postgres: 9.6/main: checkpointer process postgres 26885 0.0 0.3 236580 3664 ? Ss 10:43 0:00 postgres: 9.6/main: writer process
postgres 26886 0.0 0.2 91540 3076 ? Ss 10:43 0:00 postgres: 9.6/main: stats collector process postgres 26887 0.0 0.0 4340 700 ? S 10:43 0:00 sh -c /usr/lib/postgresql/9.6/bin/pg_standby -l -d -s 2 -r 10 /opt/archive 00000001000000040000001C pg_xlog/RECOVERYXLOG 00000001000000040000001B 2>>/tmp/pg_standby.log
postgres 26888 0.0 0.0 4232 624 ? S 10:43 0:00 /usr/lib/postgresql/9.6/bin/pg_standby -l -d -s 2 -r 10 /opt/archive 00000001000000040000001C pg_xlog/RECOVERYXLOG 00000001000000040000001B
root 26917 0.0 0.1 12732 1440 pts/2 S+ 10:43 0:00 grep postgres
Primary PostgreSQL
su - postgres
nohup /usr/lib/postgresql/9.6/bin/pg_receivexlog -h 10.0.0.180 -D /opt/archive -S repl_slot -s 5 -U repl &
Check replication lag on Standby
root@srv-test-db2: # /usr/lib/postgresql/9.6/bin/pg_controldata -D /var/lib/postgresql/9.6/main/ | grep -E '^Latest checkpoint(.s REDO)? location:'
Latest checkpoint location: 4/1B000140
Latest checkpoint's REDO location: 4/1B000108As we see replication works, but there is a slight lag. This is due to the recovery mechanism. The thing is that when you restore a wal file, pg_standby copies WAL to the pg_xlog directory and only then the recovery is done. Therefore, we will always lag behind one WAL file, although it is present in the “/opt/archive” directory in an unfinished state. In our case, such a lag is not critical.
Summary
We used the utility pg_receivexlog which allows us to use the advantages and reliability of streaming replication, as well as pg_standby for warm standby. This approach allowed us to create a replica, without significantly changing the configuration of the primary server, as well as temporarily disconnect it if necessary.
Interesting.
I once hacked together a backup system using pg_receivexlog and a warm standby for similar reasons:
https://github.com/emarsys/pgarchive/blob/master/Manual.md
Please correct me if I’m wrong but can’t one achieve the same effect with a pure streaming replication setting max_standby_streaming_delay = 5h and hot_standby_feedback = off?
Hello, Sergey! Thanks for good question!
Yes, you right, it is very similar to streaming replication, but there are some advantages in comparison with it:
1) we can split the process of transferring WA-logs and standby server. This is useful when standby is loaded and can not receive logs. In the case of streaming replication, the logs will be copied on the primary. This is not good.
2) We can also use the “copy” command instead of pg_receivexlog to further reduce the impact on primary.
3) This approach makes it possible to use a common archive for multiple servers if necessary.
4) we can stop our PostgreSQL standby server and this will not lead to the growth of WAL logs on the primary.
If for you all of the above is not necessary – use streaming replication.
Good evening, I have a lot of new customers for you. can i contact by phone?
Hello! Sure, our contacts:
+972 33 76 0357
support@awide.io
You deliberately wrote such an incomplete article, missing many settings? The article is useless.
Hi! The purpose of this article is to demonstrate a possible solution. This is not a manual for setting up production-ready configurations, so many settings are missing.
Sorry though. Got hot. Thanks for the article anyway. Got, production-ready it is not open source 🙂