Introduction
Not so long ago, one of our customers turned to us with problem. The fact is that PostgreSQL refused to use the index on the text field if you try to make a selection using regular expressions (LIKE/ILIKE and POSIX). Our colleagues wondered why Postgres does not use the index, because the database used the “universal” encoding UTF-8. Today I want to explain one fairly well-known problem in PostgreSQL. This is using locales and sorting rules. You probably ask the question: what links indexes, sorting and locale? Let’s try to understand.
LC_COLLATE
In PostgreSQL, there are several parameters that control the locale:
- LC_COLLATE String sort order
- LC_CTYPE Character classification (What is a letter? Its upper-case equivalent?)
- LC_MESSAGES Language of messages
- LC_MONETARY Formatting of currency amounts
- LC_NUMERIC Formatting of numbers
- LC_TIME Formatting of dates and times
Here is an excerpt from the documentation:
"Locale support is automatically initialized when a database cluster is created using initdb. initdb will initialize the database cluster with the locale setting of its execution environment by default, so if your system is already set to use the locale that you want in your database cluster then there is nothing else you need to do. If you want to use a different locale (or you are not sure which locale your system is set to), you can instruct initdb exactly which locale to use by specifying the --locale option."
That is, postgres always uses the locale that the OS provides to it. A list of supported character sets can be found in the documentation. Sorting rules always define two parameters: LC_COLLATE and LC_CTYPE. They can not be changed for an existing database. You ask, how does this relate to the indices?
The index btree, also B-tree, is suitable for data that can be sorted. In other words, for a data type, operators “>”, “>=”, “<“, “<=” and “=” must be defined. Here is a schematic example of an index on a single field with integer keys.
Let’s try to find the number 14:
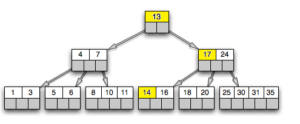
The search begins with the root node, and we need to determine which of the child nodes to descend. Knowing the key (13) in the root node, we mean the range of values in the child nodes. Since 7 ≤ 14 <17, we must go down to the second child node. We see that all the numbers are sorted and so we know which node we need to go to.
Let’s see how the index looks like in the text:
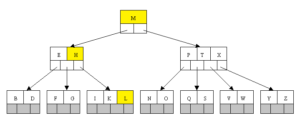
The algorithm for finding the letter “L” is similar to the search for numbers. In order to build an index, we need to know the sort order. To do this PostgreSQL used LC_COLLATE and LC_CTYPE. But as I said above, these indexes will work only for operators “>”, “> =”, “<“, “<=” and “=”. And here I would like to talk about the nuances.
For example, you installed PostgreSQL from sources and ran the initdb command. You may have installed Postgres from the packages, in which case the current OS locale is used. Most likely it will be UTF-8. But I want to upset you, sorting results will be different even when using “UTF-8” in different operating systems. Here are some links (order by different on mac vs linux, collate order on Mac OS X, text with diacritics in UTF-8) to the different sorting rules behavior in Mac OS and Linux. Moreover, they can be different if you use the same OS! That is, UTF-8 is also different. This can cause big problems when sorting the result and searching the text. This should always be remembered when you are designing a database. UTF-8 does not guarantee you a problem-free life.
But back to the indexes. Let’s look at an example:
psql (10.0)
Type "help" for help.
postgres=# CREATE TABLE foo (id serial NOT NULL, foo_text text);
CREATE TABLE
postgres=# INSERT INTO foo(foo_text) SELECT md5(row::text) FROM generate_series(1, 5000000) row;
INSERT 0 5000000
postgres=# CREATE INDEX idx_foo_text_utf8 ON foo (foo_text);
CREATE INDEX
postgres=# ANALYZE foo;
ANALYZECreating a table and inserting random data. The next step is to create an index in the “foo_text” field. The index will use the rules for sorting the locale “UTF-8”. We will perform a simple query using “LIKE” operator:
postgres=# EXPLAIN ANALYZE SELECT * FROM foo WHERE foo_text like 'a%';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..99011.67 rows=303030 width=37) (actual time=30.794..1844.541 rows=312676 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on foo (cost=0.00..67708.67 rows=126262 width=37) (actual time=0.204..769.621 rows=104225 loops=3)
Filter: (foo_text ~~ 'a%'::text)
Rows Removed by Filter: 1562441
Planning time: 0.095 ms
Execution time: 1879.400 ms
(8 rows)The index is not used. The disadvantage of using locales other than “C” or “POSIX” in Postgres is the impact on performance. This slows the processing of characters and prevents “LIKE” from using ordinary indexes. As a workaround that will allow Postgres to use indexes with “LIKE” clauses using a locale other than “C”, there are several classes of user operators. They allow you to create an index that performs a strict character-by-symbol comparison, ignoring the comparison rules corresponding to the locale.
Operator Classes
The operator classes text_pattern_ops, varchar_pattern_ops and bpchar_pattern_ops support B-tree indexes for text, varchar and char types, respectively.
Create a new index with the operator “text_pattern_ops”:
postgres=# CREATE INDEX idx_foo_text_ops ON foo (foo_text text_pattern_ops);
CREATE INDEXRepeat our query:
postgres=# EXPLAIN ANALYZE SELECT * FROM foo WHERE foo_text like 'a%';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on foo (cost=12186.05..57750.21 rows=303030 width=37) (actual time=99.554..594.368 rows=312676 loops=1)
Filter: (foo_text ~~ 'a%'::text)
Heap Blocks: exact=41647
-> Bitmap Index Scan on idx_foo_text_ops (cost=0.00..12110.29 rows=311773 width=0) (actual time=89.985..89.985 rows=312676 loops=1)
Index Cond: ((foo_text ~>=~ 'a'::text) AND (foo_text ~<~ 'b'::text))
Planning time: 1.361 ms
Execution time: 608.246 ms
(7 rows)Now Postgres uses the index and the query time has been reduced by 3 times. But this approach has its drawbacks. The classes of operators xxx_pattern_ops are not suitable for comparison with the help of the operators “<“, “<=”, “>” and “> =”. In such cases, for a column, you need to create multiple indexes with different operator classes.
COLLATE “C”
The only way out of the situation is to use the locale “C”. This locale is shipped with PostgreSQL and does not depend on the OS. Yes, it will not take into account some borderline cases in each of the languages, but it will work moderately well for everyone. He also has a big plus when searching using regular expressions. The “C” and “POSIX” sorting rules define the behavior typical of “traditional C”, in which only the ASCII character encodings from “A” to “Z” are treated as letters, and sorting is performed strictly by the symbolic byte code. If you use the locale “C”, you do not need classes of xxx_pattern_ops operators, because for the search in the locale C, there will be enough indexes with the default class of operators.
Create a new index with COLLATE “C”:
postgres=# CREATE INDEX idx_foo_text_collate_c ON foo (foo_text COLLATE "C");
CREATE INDEXRepeat our query:
postgres=# EXPLAIN ANALYZE SELECT * FROM foo WHERE foo_text like 'a%';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on foo (cost=12186.05..57750.21 rows=303030 width=37) (actual time=102.845..569.178 rows=312676 loops=1)
Filter: (foo_text ~~ 'a%'::text)
Heap Blocks: exact=41647
-> Bitmap Index Scan on idx_foo_text_collate_c (cost=0.00..12110.29 rows=311773 width=0) (actual time=93.220..93.220 rows=312676 loops=1)
Index Cond: ((foo_text >= 'a'::text) AND (foo_text < 'b'::text))
Planning time: 0.183 ms
Execution time: 583.056 ms
(7 rows)The query plan differs from the previous one. The planner uses standard comparison operators, but uses the index.
ICU support in PostgreSQL 10
International Components for Unicode (ICU) is a library that provides opportunities for internationalization and localization, including sorting. Therefore, in this respect, this is an alternative to using the tools in the standard C library. Peter Eisentraut recently wrote a very good article on this topic in his blog.
The ICU gives guarantees that the collation will not change when upgrading the minor version. We can also check the version of collation. One of the good optimizations that emerged with the release of PostgreSQL 9.5 was abbreviated keys. This optimization greatly accelerated the sorting of text fields and the creation of indexes on them. Unfortunately, in 9.5.2 this optimization was turned off for all collation except “C”. The cause was a bug in glibc (for all collation except “C” PostgreSQL relies on glibc), as a result of which the indices could turn out to be inconsistent. The IСU can solve this problem. In this way, we will get an improvement in performance.
Let’s try to create a table using this library:
postgres=# CREATE TABLE foo2 (id serial NOT NULL, foo_text text COLLATE "en-x-icu");
CREATE TABLE
postgres=# INSERT INTO foo2(foo_text) SELECT md5(row::text) FROM generate_series(1, 5000000) row;
INSERT 0 5000000
postgres=# ANALYZE foo2;
ANALYZE
postgres=# CREATE INDEX idx_foo2_text_collate_icu ON foo2 (foo_text);
CREATE INDEXExecute our query:
postgres=# EXPLAIN ANALYZE SELECT * FROM foo2 WHERE foo_text like 'a%' ;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..99011.67 rows=303030 width=37) (actual time=42.891..3765.683 rows=312676 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on foo2 (cost=0.00..67708.67 rows=126262 width=37) (actual time=19.848..2803.506 rows=104225 loops=3)
Filter: (foo_text ~~ 'a%'::text)
Rows Removed by Filter: 1562441
Planning time: 655.622 ms
Execution time: 3805.448 ms
(8 rows)Unfortunately, the index is not used. We still need to use the text_pattern_ops operator:
postgres=# CREATE INDEX idx_foo2_text_collate_icu ON foo2 (foo_text text_pattern_ops);
CREATE INDEXQuery:
postgres=# EXPLAIN ANALYZE SELECT * FROM foo2 WHERE foo_text like 'a%' ;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on foo2 (cost=12121.24..57664.39 rows=303030 width=37) (actual time=97.711..676.348 rows=312676 loops=1)
Filter: (foo_text ~~ 'a%'::text)
Heap Blocks: exact=41647
-> Bitmap Index Scan on idx_foo2_text_collate_icu (cost=0.00..12045.48 rows=310092 width=0) (actual time=88.189..88.189 rows=312676 loops=1)
Index Cond: ((foo_text ~>=~ 'a'::text) AND (foo_text ~<~ 'b'::text))
Planning time: 0.170 ms
Execution time: 693.799 ms
(7 rows)Summary
As we see collate and sorting this is a very difficult tasks that has many problems. Today, we tried to understand how PostgreSQL uses locals. Fortunately, in the PostgreSQL 10t , the developers added support for the ICU library. Of course, this is only the beginning, and the functionality will expand, but this is a big step towards solving existing problems.
Thank’s and waiting for new features!